Annoteren kun je leren!
CREATE IIIF / Linked Open Data - Datasprint
- Datum
- 17 oktober 2024
- Tijd
- 12:30 -16:30
- Locatie
- Bushuis/Oost-Indisch Huis
- Ruimte
- Workshopruimte Humanities Labs, F0.01

Wat ga je doen?
Hoe werkt dat eigenlijk, annoteren? Wat zijn manifesten en welke tools zijn er nu al beschikbaar om gedigitaliseerd materiaal te verrijken? Hoe kan een erfgoedinstelling ervoor zorgen dat digitale bronnen geannoteerd kunnen worden door anderen en als Linked Open Data voor iedereen beschikbaar komen om verder verrijkt te worden? En hoe zorg je ervoor dat al die informatie ook door anderen gevonden en gebruikt kan worden?
In deze datasprint gaan we in kleine groepjes aan de slag met verschillende soorten archiefmateriaal uit de collectie van het Stadsarchief Amsterdam, de kaartcollectie van het Allard Pierson en een van de dagboeken uit de Amsterdam Diaries Time Machine om zo te proberen antwoord op deze vragen te krijgen. We kijken welke soorten annotaties we kunnen maken op dit materiaal (tags, transcripties, identificatie, etc.), hoe we die informatie het beste kunnen modelleren en hoe die manier aansluit bij andere Linked Open Databronnen (bijvoorbeeld inventarissen in RiC-O, thesauri in SKOS, of andere entiteiten in Wikidata) en onderzoek.
De uitkomst van de datasprint levert hopelijk nieuwe inzichten op over hoe we onze data op een gestandaardiseerde manier eenvoudiger met elkaar kunnen delen. Hiervoor werken we toe naar een best practice van een gedeeld 'IIIF Canvas' voor archiefdocumenten.
Sessies

In deze sessie gaan we dieper in op de transformatie van traditionele archiefbeschrijvingen naar Linked Open Data (in het bijzonder de publicatie als IIIF Manifest). We bespreken hoe archiefinstellingen de overgang kunnen maken van fysieke beschrijvingen naar gedigitaliseerde en geannoteerde versies van hun materiaal. Hierbij wordt aandacht besteed aan het creëren van consistente metadata die kunnen aansluiten bij internationale standaarden zoals RiC-O. Het doel is om deelnemers te laten zien hoe traditionele archiefdata door middel van digitalisering toegankelijker en rijker kunnen worden, waardoor deze bronnen nieuwe kansen bieden voor onderzoek en hergebruik.
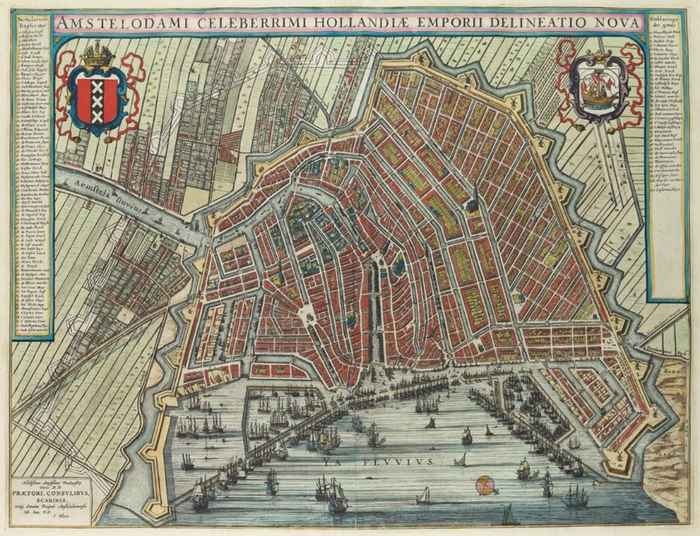
Deze sessie richt zich specifiek op het werken met historisch kaartmateriaal en atlassen. Deelnemers krijgen de kans om te leren hoe kaarten kunnen worden geannoteerd en verrijkt met behulp van Allmaps en een visuele annotatietool. We kijken hoe verschillende soorten annotaties elkaar kunnen aanvullen. Immers, als je toponiemen annoteert en linkt, dan wordt het eenvoudiger om een kaart te georefereren, en vice versa. De sessie laat zien hoe digitale kaarten niet alleen geografische informatie verstrekken, maar ook als waardevolle bronnen voor historisch onderzoek kunnen dienen.

In deze sessie duiken we in de digitale annotatie van oorlogsdagboeken uit de Tweede Wereldoorlog, een project van de Amsterdam Diaries Time Machine. Deelnemers krijgen de kans om te werken met persoonlijke getuigenissen en verhalen uit deze periode en ontdekken hoe deze documenten kunnen worden verrijkt met metadata, transcripties, en contextuele informatie. Het project streeft ernaar om deze historische bronnen toegankelijker te maken voor een breed publiek en tegelijkertijd nieuwe inzichten te genereren door ze te koppelen aan andere bronnen en gegevens uit die tijd, zoals foto’s en persoonskaarten.
Programma
12:30 uur: Inloop - ontvangst met koffie/thee
13.00 uur: Welkom en inleiding
13.30 uur: Kennismakings-intermezzo
13:45 uur: Werken met de data
15:15 uur: Thee/koffie
15.30 uur: Korte presentatie per groep - bespreking vervolg
16.30 uur: Borrel
Programma
Deelname is gratis, voor koffie, thee en de borrel wordt gezorgd. Wel graag even aanmelden op amsterdamtimemachine@uva.nl. Sluitingsdatum aanmelding (i.v.m. de catering): vrijdag 11 oktober 2024.
