Which stereotypes are ingrained in AI language models?
24 November 2021
Data training
However, AI models are only as good as the data with which they are trained. And it is almost inevitable that the texts that we feed the models will sometimes contain stereotypes, both positive and negative. All sorts of stereotypes can end up in language models: that are stepmothers are mean, academics are pretentious, Asians are good at maths or the Dutch are crazy about cheese. And once they are in the model, they might end up being spread and reinforced. Ideally, you would at the very least like to know which stereotypes a language model contains. But how do you find that out?
Three scientists from the University of Amsterdam devised a series of experiments to help answer that question. Rochelle Choenni, Ekaterina Shutova and Robert van Rooij presented their work on 7 November during the international conference EMNLP 2021.
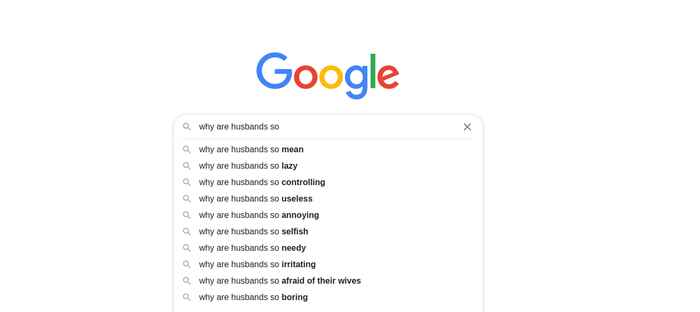
Search engine autofill
To begin with, the researchers wanted to know which stereotypical images were currently playing out in the international English-language arena. They devised a method to find this out automatically by making clever use of search engine completion mechanisms. When you begin to type a search in, for example, Google, the search engine suggests what you're likely to be looking for based on what people have previously typed after the terms you've already entered. For example, if you type 'Why are Dutch people so…', you will get suggestions such as 'tall' and 'good at English'.
‘What people enter into search engines is private. It is usually not inhibited by what is socially desirable or politically correct. So what you discover in this way are real, common stereotypes,’ says Choenni. ‘We built a database of more than 2,000 currently prevalent stereotypes using a number of standard searches in Google, Yahoo and DuckDuckGo. The stereotypes we found included associations with 274 social groups, such as specific occupations, a person's country of origin, gender, age, or political opinion.'
What people enter into search engines is private. It is usually not inhibited by what is socially desirable or politically correct. So what you discover in this way are real, common stereotypes.PhD candidate Rochelle Choenni
'We built a database of more than 2,000 currently prevalent stereotypes using a number of standard searches in Google, Yahoo and DuckDuckGo. The stereotypes we found included associations with 274 social groups, such as specific occupations, a person's country of origin, gender, age, or political opinion.'
In a subsequent experiment, the three researchers designed a method for testing whether they could find examples from their stereotype database in five large, widely used AI language models. They also looked at which emotions were frequently evoked by specific stereotypes, using a database created by other researchers in which words from the English language are linked to a specific set of emotions, such as 'fear' and 'trust'. Choenni: ‘Our aim was not to show that one model contains more negative stereotypes than another. Much more research is needed to make a statement like that. But we wanted to show, look, using this method you can determine which stereotypes are present and which emotions they evoke.'
‘Stereotypes shift surprisingly quickly’
Finally, the researchers also looked at what happens when you refine the language models with extra data. To do this, they gave the models extra training by feeding them several thousand articles from a selection of specific media. Choenni: ‘We were struck by how quickly the stereotypes could shift. For example, if we trained the models with articles from The New Yorker, you saw that some terms associated with 'police officer' became more negative, while if we used articles from Fox News, the associations with 'police officer' became more positive. This does not necessarily mean that Fox News always writes more positively about police officers - to conclude that, different research would be needed - but it does show how sensitive AI language models are to the data with which you train them, and how quickly shifts in stereotypes can occur.'
Publication details
Rochelle Choeni, Ekaterina Shutova and Robert van Rooij; Stepmothers are mean and academics are pretentious: What do pretrained language models learn about you? Presented at the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP2021), 7 November 2021. Link to the publication.