Master AI Student Publishes in Most Prestigious AI Conference
6 April 2023
Do Video-Language Models Sense Time?
The introduction of ChatGPT has brought Large Language Models into mainstream discussions as a truly transformational technology. Recently released GPT-4 goes a step further and takes in images along with language. Although in nascence, this tide of large foundation models has also made its way into video understanding with increasingly capable video-language models emerging as we speak. Note that training such foundation models from scratch requires tremendous amounts of compute and data. Given the essence of understanding time progression in a video, in this work, the authors ask: do such video-language foundation models sense time? If not, can we instil this sense in them without the massively expensive re-training from scratch?

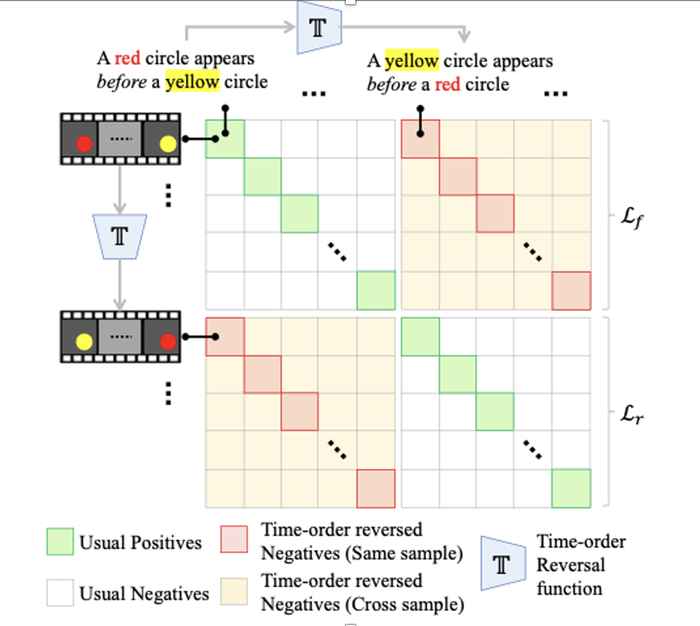
What does it mean to have a sense of time? The authors start with a simple definition that concerns understanding before/after relations in language and connecting them with the video (as illustrated in the GIF above). They find that seven of the existing video-language models lack this sense of time. Next, they ask if it is possible to instil this sense into a given model without re-training the model completely from scratch. Towards this, the solution was to propose a simple recipe to do this using contrastive learning where they the model was asked to pull together the video and a time-order consistent sentence and push apart the video and an inconsistent sentence (as shown in the GIF below). More details on the proposed method can be found in the paper (links provided at the end). By not training from scratch, it becomes possible to preserve the original spatial abilities of the model while adding this new temporal ability. The authors demonstrate the effectiveness of this recipe with one such video-language model on a diverse set of real-world datasets. Finally, the authors also show that a time-aware model trained with our recipe can also generalize to previously unseen tasks that need temporal reasoning.
Amsterdam Merit Scholarship
Piyush is a recipient of the Amsterdam Merit Scholarship which supports international students studying in the Master’s programmes at the University of Amsterdam. Recently, he was also selected as an ELLIS Honors Student to pursue his Master’s thesis advised by Prof. Cees Snoek in collaboration with Prof. Andrew Zisserman at the University of Oxford. He is currently visiting Oxford as part of the same ELLIS program.
More information
Paper: https://arxiv.org/abs/2301.02074
Project page: https://bpiyush.github.io/testoftime-website/
Code: https://github.com/bpiyush/TestOfTime